
Chatten mit den eigenen Firmendaten: Einführung in Retrieval Augmented Generation (RAG)
Kennst du das? Du suchst eine ganz bestimmte Info und klickst dich (gefühlt ewig) durch Ordner, E-Mails und Wikis. Dabei wolltest du doch einfach nur eine schnelle Antwort. Genau hier setzt Retrieval Augmented Generation an. Kurz: RAG. Ein Ansatz, der die Stärken von Chatbots und Sprachmodellen mit internem Firmenwissen verbindet.
Über 60% der Schweizer:Innen nutzen generative KI-Chatbots wie ChatGPT oder Gemini regelmässig. Auch im Büroalltag werden KI-Tools immer mehr zur Effizienzsteigerung eingesetzt. Mitarbeitende erleben aber schnell deren Grenzen: ungenaue Antworten, fehlender Bezug zum Unternehmen, keine Verbindung zu internen Daten. Das Problem: Die Chatbots wissen nichts über interne Richtlinien oder spezifische Produkte und Prozesse. Retrieval Augmented Generation löst genau dieses Problem.
In diesem Beitrag erfährst du, was RAG ist, wie die Technologie dahinter funktioniert und wie ihr sie im Unternehmen gezielt für die Abfrage von internem Wissen nutzen könnt.
Was ist Retrieval Augmented Generation (RAG)?
RAG ist ein technischer Ansatz, der einem KI-Chatbot ermöglicht, kontrolliert auf internes Firmenwissen zuzugreifen. Die Systeme können Informationen wie Richtlinien in SharePoint, technische Handbücher im PDF-Archiv oder Protokolle durchsuchen, verknüpfen und im Chat nutzbar machen.
Das Prinzip ist einfach: RAG kombiniert drei Elemente zu einem System, das interne Informationen im Chat nutzbar macht.
- Eine intelligente Suche, die relevante Inhalte aus internen Dokumenten oder Datenquellen identifiziert
- Ein Sprachmodell (LLM), das diese Inhalte in verständlicher Sprache zusammenfasst
- Und ein Chatinterface, über das Nutzer:innen Fragen stellen und sofort passende Antworten erhalten können
So wird aus internen Daten ein nutzbarer Wissensspeicher. Ohne stundenlanges Durchforsten von Dateien.
Ausbaustufen von KI-Chatbots: Wo steht dein Unternehmen gerade?
Je nachdem, wie weit dein Unternehmen bereits mit KI-Anwendungen ist, kann ein Chatbot unterschiedliche Reifegrade erreichen. Hier sind vier typische Stufen:
- Stufe 1: Generisch
Der Chatbot beantwortet allgemeine Fragen wie „Wie viele Ferientage sind in der Schweiz gesetzlich vorgeschrieben?“, basierend auf öffentlich zugänglichen Quellen. Ideal für den Einstieg mit Tools wie ChatGPT oder Copilot. - Stufe 2: Firmenwissen
Jetzt wird es spezifischer. Der Bot greift auf interne Dokumente zu, etwa HR-Richtlinien. So lassen sich Fragen wie „Wie viele Ferientage hat ein:e Mitarbeiter:in auf Stufe X bei uns?“ beantworten. Voraussetzung ist eine durchsuchbare Wissensbasis. - Stufe 3: Individuell
Der Chatbot erkennt den Kontext der anfragenden Person und gibt personalisierte Antworten wie „Wie viele Ferientage habe ich noch?“. Dafür braucht es eine Schnittstelle zu personenbezogenen Daten und eine Rechteverwaltung. - Stufe 4: Aggregiert
Komplexe, übergreifende Fragen wie „Wie viele Restferientage hat das gesamte Marketing-Team?“ werden möglich. Das erfordert Datenbankintegration, Berechnungslogik und ein sauberes Berechtigungskonzept.
Mit RAG können Unternehmen gezielt auf diese Stufen hinarbeiten, je nach Bedarf und Reifegrad.
Wie ist ein RAG-Chatbot aufgebaut?
Ein produktiver RAG-Chatbot basiert auf drei zentralen Elementen (Abbildung 1):
Wissensdatenbank (aka database / DB): Alle relevanten Inhalte werden gesammelt, bereinigt und in einer durchsuchbaren Datenstruktur gespeichert, zum Beispiel in einer Vektor-Datenbank. Hier landen Handbücher, interne Wikis oder Richtliniendokumente.
Sprachmodelle (aka Large Language Model): Zwei Modelle kommen zum Einsatz. Eines erzeugt Vektoren (Embeddings) für die Inhalte, das andere generiert verständliche Antworten auf Basis der Suchtreffer (Completion).
Chatbot-Agent: Dieser steuert die Kommunikation zwischen Nutzer:in, Wissensdatenbank und Sprachmodell. Er sorgt dafür, dass alle Teile zusammenarbeiten und bei Bedarf externe Schnittstellen einbezogen werden können.
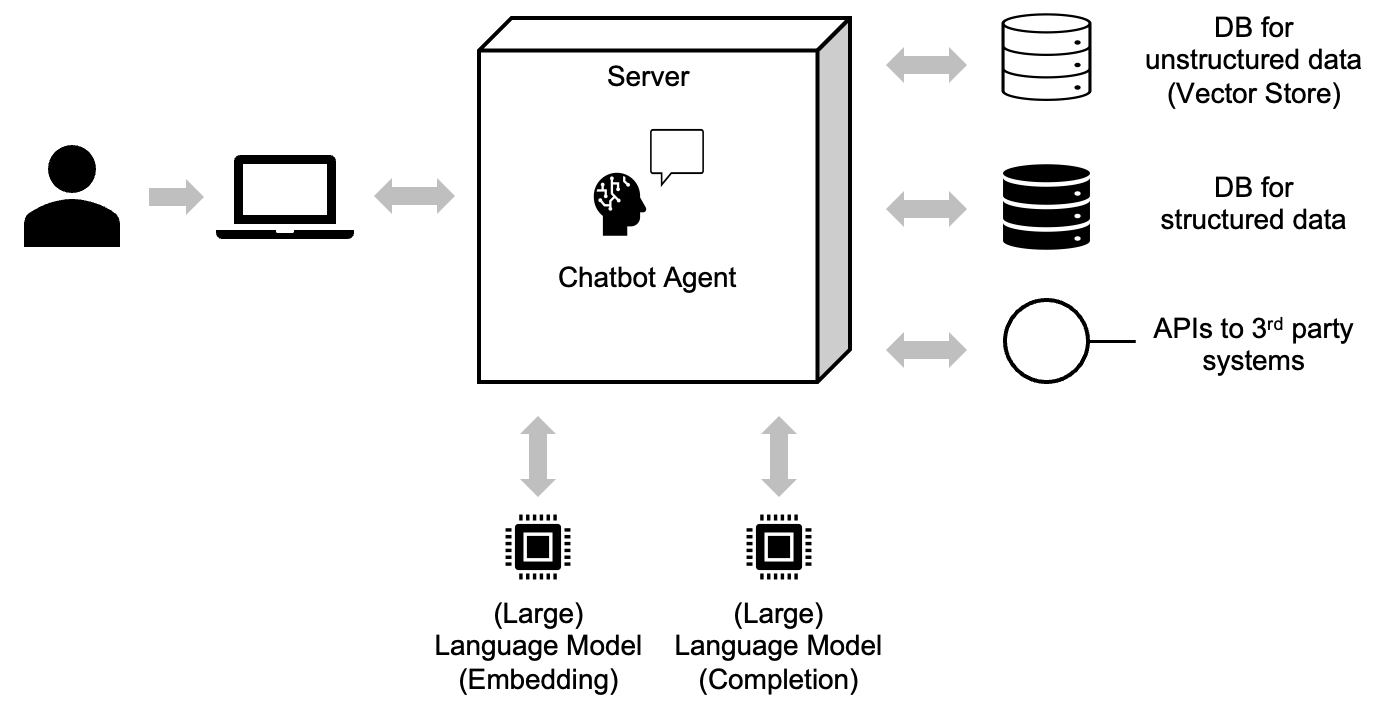
Abbildung 1: Aufbau eines RAG-Chatbots
Wie funktioniert RAG technisch? Schritt für Schritt erklärt
Damit ein RAG-System überhaupt funktioniert, braucht es zwei Phasen: die Vorbereitung und die Nutzung. Klingt simpel, ist aber technisch anspruchsvoll. Wir erklären es dir hier ganz ohne Fachchinesisch.
Phase 1: Vorbereitung (Indexierung)
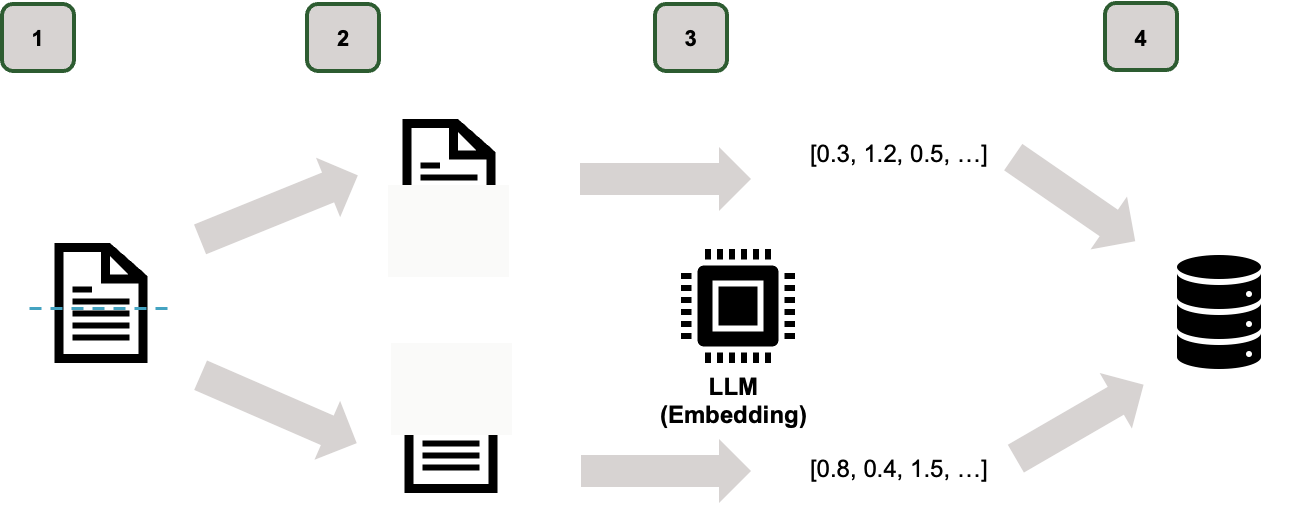
Abbildung 2: RAG Schritt-für-Schritt (Phase 1)
Bevor ein Chatbot mit den firmeninternen Daten arbeiten kann, muss er sie zunächst in eine für ihn verständliche Form bringen. Das passiert in vier Schritten:
- 1. Dokumente sammeln und lesbar machen: Im ersten Schritt werden alle relevanten Dokumente zusammengetragen. Das können PDF-Dateien, Word-Dokumente oder auch Inhalte aus einem Intranet oder Wiki sein. Wichtig ist, dass die Inhalte digital lesbar sind. Wenn ihr zum Beispiel nur Scans hast, wird eine Texterkennung (OCR) nötig, um den Text maschinenlesbar zu machen.
- 2. In sinnvolle Abschnitte zerlegen (Chunking): Ein Dokument als Ganzes ist zu gross, um effizient durchsucht zu werden. Deshalb wird es in kleinere Einheiten aufgeteilt, sogenannte „Chunks“. Das können Absätze, Kapitel oder einzelne Aufzählungspunkte sein. Diese Einheiten lassen sich später gezielt abrufen.
- 3. Bedeutung als Zahlencode erfassen (Embeddings): Jeder dieser Chunks wird nun von einem Sprachmodell analysiert. Das Modell wandelt den Text in einen Vektor um, also eine Art Zahlencode, der zusammenfasst, worum es inhaltlich geht. Diese Vektoren machen es möglich, später nicht nur nach Stichworten, sondern nach Bedeutung zu suchen.
- 4. Speichern in einer semantischen Suchmaschine: Die Vektoren samt zugehörigem Textabschnitt werden in einer Vektordatenbank gespeichert. Diese Datenbank funktioniert wie eine Suchmaschine, aber statt nach genauen Wörtern sucht sie nach ähnlicher Bedeutung. So können später auch Fragen beantwortet werden, die anders formuliert sind als der Originaltext.
Jetzt ist das Wissen bereit zur Nutzung.
Phase 2: Nutzung (Querying)
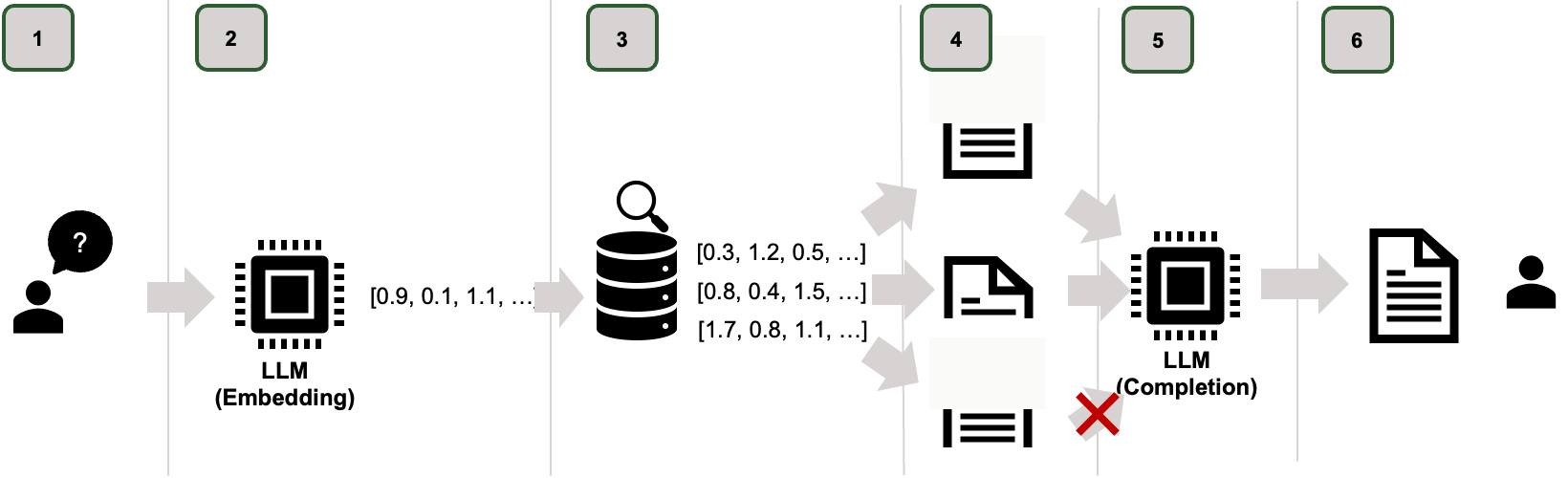
Abbildung 3: RAG Schritt-für-Schritt (Phase 2)
Wenn Mitarbeitende später Fragen an das System stellen, läuft im Hintergrund Folgendes ab:
- 1. Frage eingeben: Ein:e Mitarbeiter:In stellt eine konkrete Frage im Chatfenster.
- 2. Die Frage wird in einen Vektor übersetzt: Das System wandelt auch die Frage in einen Zahlenvektor um, nach dem gleichen Prinzip wie zuvor bei den Dokumenten.
- 3. Relevante Inhalte finden: Die Vektordatenbank vergleicht die Frage mit den gespeicherten Vektoren und sucht die Abschnitte heraus, die inhaltlich am besten passen.
- 4. Textabschnitte werden geladen: Die gefundenen Inhalte (zum Beispiel die fünf passendsten Abschnitte) werden aus der Datenbank abgerufen.
- 5. Antwort wird formuliert: Ein Sprachmodell liest die geladenen Abschnitte und formuliert daraus eine verständliche, zusammenhängende Antwort.
- 6. Antwort im Chat anzeigen: Die fertige Antwort erscheint direkt im Chatfenster, idealerweise mit Quellenangabe, damit man nachvollziehen kann, woher die Information stammt.
Was Unternehmen vor dem Start klären sollten
Bevor ihr als Unternehmen mit RAG loslegt, solltet ihr euch ein paar zentrale Fragen stellen:
- Sind eure wichtigsten Dokumente digital verfügbar und gut auffindbar? Wenn Informationen über mehrere Tools verstreut sind, lohnt sich ein Vorprojekt zur Konsolidierung.
- Wie aktuell sind eure Inhalte? Veraltete Policies führen zu falschen Antworten. Eine regelmässige Aktualisierung ist entscheidend.
- Wer darf auf welche Informationen zugreifen? Ohne klares Berechtigungskonzept funktioniert kein verantwortungsvoller Chatbot.
- Wie gelangen neue Daten ins System? Eine manuelle Pflege ist fehleranfällig. Automatisierte Workflows sparen Zeit und sichern Qualität.
Diese Fragen bilden die Grundlage für eine stabile RAG-Lösung.
Der AI Accelerator: RAG umsetzen, ohne bei null anzufangen
Ihr möchtet im Unternehmen RAG einsetzen, habt aber keine Zeit, euch durch jedes technische Detail zu kämpfen?
Der Swiss GenAI Accelerator unterstützt Unternehmen genau dabei. In drei Monaten entwickelt ihr mit eurer internen Expertise und externer Begleitung eine funktionierende RAG-Anwendung.
- Im Use Case Sprint definieren wir gemeinsam, wo der grösste Mehrwert liegt.
- In der Build Phase entsteht ein funktionsfähiger Prototyp, unterstützt durch erfahrene Fachpersonen.
- In der Go-Live-Phase lernt ihr, wie ihr euer System betreibt, weiterentwickelt und skaliert – inklusive Governance, Datenpflege und Prompt-Design.
Um am Programm teilzunehmen braucht ihr keine Vorerfahrung mit KI oder LLMs. Was zählt, ist ein konkreter Anwendungsfall und ein motiviertes Team. Schau dir hier die Details zum Accelerator an und finde heraus, ob das Programm der passende nächste Schritt für dein Unternehmen ist.